



Author: DS Sarah Nguyen
We are living and working in a time that is all about data. Data is the lifeblood of any enterprise, which means data is among any enterprise’s most valuable possessions. Applications, services, software, mobile devices, and other elements combine to form an intricate and far-reaching web that touches and affects most areas of our lives.

As a result, there’s an increased need to handle information flow between these different elements. Devices and apps need to talk to each other, and there is no room for error. That’s why it is important to consider the most suitable message brokers and similar tools to communicate with each other and minimize mistakes.
1. What is the difference between a message broker and a Pub/sub messaging system?
Message brokers are software modules that let applications, services, and systems communicate and exchange information. Message brokers do this by translating messages between formal messaging protocols, enabling interdependent services to directly “talk” with one another, even if they are written in different languages or running on other platforms.
Message brokers validate, route, store, and deliver messages to the designated recipients. The brokers operate as intermediaries between other applications, letting senders issue messages without knowing the consumers’ locations, whether they’re active or not, or even how many of them exist.
However, Publish/Subscribe is a message distribution pattern that lets producers publish each message they want.
Data engineers and scientists refer to pub/sub as a broadcast-style distribution method, featuring a one-to-many relationship between the publisher and the consumers.
2. What is Kafka? What is RabbitMQ?
2.1 What is Kafka?
Kafka is an open-source distributed event streaming platform, facilitating raw throughput. Written in Java and Scala, Kafka is a pub/sub message bus geared towards streams and high-ingress data replay. Rather than relying on a message queue, Kafka appends messages to the log and leaves them there, where they remain until the consumer reads it or reaches its retention limit.
Kafka employs a “pull-based” approach, letting users request message batches from specific offsets. Users can leverage message batching for higher throughput and effective message delivery.
Although Kafka only ships with a Java client, it offers an adapter SDK, allowing programmers to build their unique system integration. There is also a growing catalog of community ecosystem projects and open-source clients.
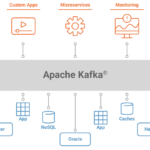
2.2 What is RabbitMQ?
RabbitMQ is an open-source distributed message broker that facilitates efficient message delivery in complex routing scenarios. It’s called “distributed” because RabbitMQ typically runs as a cluster of nodes where the queues are distributed across the nodes — replicated for high availability and fault tolerance.
RabbitMQ employs a push model and prevents overwhelming users via the consumer configured prefetch limit. This model is an ideal approach for low-latency messaging. It also functions well with the RabbitMQ queue-based architecture. Think of RabbitMQ as a post office, which receives, stores, and delivers mail, whereas RabbitMQ accepts, stores, and transmits binary data messages.
RabbitMQ natively implements AMQP 0.9.1 and uses plug-ins to offer additional protocols like AMQP 1.0, HTTP, STOMP, and MQTT. RabbitMQ officially supports Elixir, Go, Java, JavaScript, .NET, PHP, Python, Ruby, Objective-C, Spring, and Swift. It also supports various dev tools and clients using community plug-ins.
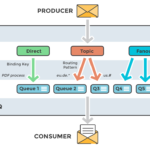
3. What is the difference between Kafka and RabbitMQ?
Here are some of top differences between Kafka and RabbitMQ:
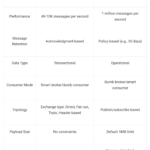
4. What is Kafka used for? What is RabbitMQ used for?
4.1 What is Kafka used for?
Kafka is best used for streaming from A to B without resorting to complex routing, but with maximum throughput. It’s also ideal for event sourcing, stream processing, and carrying out modeling changes to a system as a sequence of events. Kafka is also suitable for processing data in multi-stage pipelines.
4.2. Data analysis: tracking, ingestion, logging, security
In all these cases, large amounts of data need to be collected, stored, and handled. Companies that need to gain insights into data, provide search features, auditing or analysis of tons of data justify the use of Kafka.
According to the creators of Apache Kafka, the original use case for Kafka was to track website activity including page views, searches, uploads or other actions users may take. This kind of activity tracking often requires a very high volume of throughput, since messages are generated for each action and for each user. Many of these activities – in fact, all of the system activities – can be stored in Kafka and handled as needed.
Producers of data only need to send their data to a single place while a host of backend services can consume the data as required. Major analytics, search and storage systems have integrations with Kafka.
Kafka can be used to stream large amounts of information to storage systems, and these days hard drive space is not a large expense.
4.3 Real-time processing
Kafka acts as a high-throughput distributed system; source services push streams of data into the target services that pull them in real-time.
Kafka could be used in systems handling many producers in real-time with a small number of consumers; i.e. financial IT systems monitoring stock data.
Streaming services from Spotify to Rabobank publish information in real-time over Kafka. The ability to handle high-throughput in real-time empowers applications., making these applications more powerful than ever before.
CloudAMQP uses RabbitMQ in the automated process of server setups, but we have used Kafka when publishing logs and metrics.
Bottom line, use Kafka if you need a framework for storing, reading, re-reading, and analyzing streaming data. It’s ideal for routinely audited systems or that store their messages permanently. Breaking it down even further, Kafka shines with real-time processing and analyzing data.
5. What is RabbitMQ used for?
Developers use RabbitMQ to process high-throughput and reliable background jobs, plus integration and intercommunication between and within applications. Programmers also use RabbitMQ to perform complex routing to consumers and integrate multiple applications and services with non-trivial routing logic.
RabbitMQ is perfect for web servers that need rapid request-response. It also shares loads between workers under high load (20K+ messages/second). RabbitMQ can also handle background jobs or long-running tasks like PDF conversion, file scanning, or image scaling.
5.1 Long-running tasks
Message queues enable asynchronous processing, meaning that they allow you to put a message in a queue without processing it immediately. RabbitMQ is ideal for long-running tasks.
An example can be found in our RabbitMQ beginner guide, which follows a classic scenario where a web application allows users to upload information to a web site. The site will handle this information, generate a PDF, and email it back to the user. Completing the tasks in this example case takes several seconds, which is one of the reasons why a message queue will be used.
Many of our customers let RabbitMQ queues serve as event buses allowing web servers to respond quickly to requests instead of being forced to perform computationally intensive tasks on the spot.
5.2 Middleman in a Microservices architecture
RabbitMQ is also used by many customers for microservices architecture, where it serves as a means of communicating between applications, avoiding bottlenecks passing messages
Summing it up, use RabbitMQ with long-running tasks, reliably running background jobs, and communication/integration between and within applications.
6. Next steps
Sun Highway Messaging Service (Sun Highway) is a fully managed service that makes it easy for you to build and run microservices or applications that use Apache Kafka to process asynchronous communication data or streaming data. You will get a replicated brokers cluster and streaming platform that’s fully compatible with Kafka clients with the ability of handling million messages exchange, data backup with unlimited storage, high network bandwidth, high security and reliability.

Huong Nguyen (Sarah)
Digital Specialist
I am a Digital Specialist on Sunteco | Get blogs and the latest technology news and other cool stuff related to the (Container | Messaging | VM).